资料说明:包括数据+代码+文档+代码讲解。 1.项目背景 2.数据获取 3.数据预处理 4.探索性数据分析 5.特征工程 6.构建聚类模型 7.结论与展望
”kmeans 算法 学习 聚类 分类“ 的搜索结果
kmeans聚类分析,无监督学习实现Matlab代码

kmeans聚类分析,无监督学习实现Matlab代码

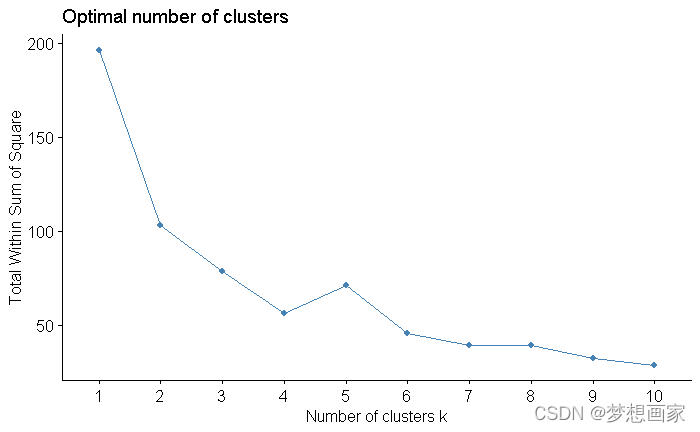
Kmeans聚类算法-手肘法,jupyter notebook 编写,打开可以直接运行,使用iris等5个数据集,机器学习。
无监督学习-kmeans聚类算法及手动实现jupyter代码.ipynb
实验报告——Kmeans聚类方法.docx
对数据进行KMeans聚类分析并可视化聚类结果 亲测能成功跑出来的KMeans算法代码
3.2.1 手动设定聚类数(也可以用轻代码)1. K-means算法的核心思想。下图分别为k=3,2,4的结果。3.2.2.1 计算标准。3.1 生成一个数据集。3.2 聚类值K的设定。2. 优化设计的关键。
在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。本文提出了一种能够...



通过实际Demo例子介绍如何采用K-Means算法完成聚类任务
基于KMeans聚类的协同过滤推荐算法可运用于基于用户和基于项目的协同过滤推荐算法中,作为降低数据稀疏度和提高推荐准确率的方法之一,一个协同过滤推荐过程可实现多次KMeans聚类。 一、基于KMeans聚类的协同过滤...
机器学习算法 机器学习算法之KMeans聚类算法实现
Kmeans++的主要原理是:逐个选取k个簇中心...Kmeans++的产生主要用于解决聚类结果严重依赖簇中心初始位置的问题;2.聚类结果严重依赖簇中心初始位置;1.需要预习确定分类的簇数;其它步骤等同Kmeans;3.对噪声数据敏感;
利用K-means算法实现聚类分析可视化
Kmeans算法是一种无监督学习方法,能够自动地将数据集中的对象划分为K个不同的聚类,每个聚类内的对象具有相似的特性。在银行客户分类中,Kmeans算法可以帮助银行识别不同的客户群体,进而为这些群体提供定制化的...
本实验基于KMeans算法对超市客户进行了聚类分群。通过对客户购物数据进行聚类,我们成功将客户分为不同的群体。每个群体代表了具有相似购物行为和偏好的客户群体。通过实验结果,我们发现了客户群体之间的明显差异和...
机器学习中有两类的大问题,一个是分类,一个是聚类。分类是监督学习,原始数据有标签,可以根据原始数据建立模型,确定新来的数据属于哪一类。聚类是一种无监督学习,聚类是指事先没有“标签”,在数据中发现数据...
K-means算法是聚类中的经典算法,数据挖掘十大经典算法之一。 算法接受参数k,然后将事先输入的n个数据对象划分k个聚类;同一聚类中的对象相似度较高;不同聚类中的对象相似度较小。 算法思想: 以空间中k...
下面是一个用 Python 实现 K-Means 聚类的代码示例: ...def kmeans(X, k, max_iterations=100): # 随机选择 k 个初始聚类中心 centers = X[np.random.choice(X.shape[0], k, replace=False), :] for i in ra...
Kmeans 聚类算法是一种常用的聚类算法,它的原理是将数据划分为k个簇,每个簇由距离中心最近的数据点组成。算法首先随机选取k个中心点,然后将每个数据点指派到距离它最近的中心点所在的簇。接下来,算法会调整每个...
推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地